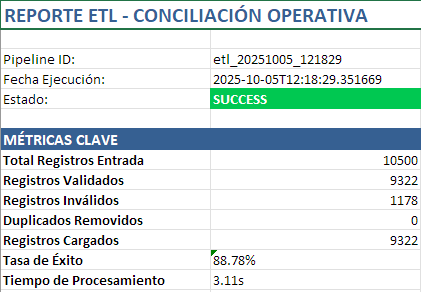
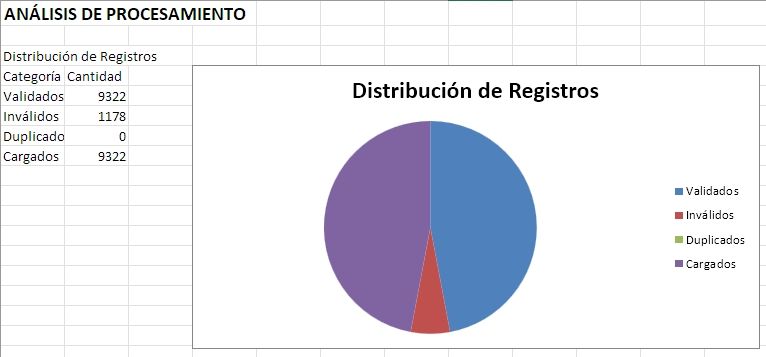
Ejecución real del pipeline
Salida directa de consola (última exitosa).
Ver logs
======================================================================
ETL PIPELINE EXECUTION
======================================================================
Input file: data/input/operaciones_demo_2025.csv
Database: sqlserver
======================================================================
2025-10-05T17:18:29.351669Z [info ] pipeline_started [__main__] input_file=data/input/operaciones_demo_2025.csv pipeline_id=etl_20251005_121829
2025-10-05T17:18:29.352669Z [info ] extraction_started [__main__] file=data/input/operaciones_demo_2025.csv
2025-10-05T17:18:29.383177Z [info ] extraction_completed [__main__] rows=10500
2025-10-05T17:18:29.383177Z [info ] validation_started [__main__] input_rows=10500
2025-10-05T17:18:31.986742Z [info ] validation_completed [__main__] invalid_rows=1178 success_rate=0.8878095238095238 valid_rows=9322
2025-10-05T17:18:31.986742Z [info ] deduplication_started [__main__] input_rows=9322
2025-10-05T17:18:31.989706Z [info ] deduplication_completed [__main__] duplicates_found=0 duplicates_removed=0 final_rows=9322
2025-10-05T17:18:32.028083Z [info ] loading_started [__main__] database=sqlserver rows=9322
Connected to SQL Server
Database: ETL_Conciliacion
Table 'dbo.operaciones' created/verified
2025-10-05T17:18:32.458621Z [info ] loading_completed [__main__] rows_failed=0 rows_inserted=9322 rows_updated=0
Database connection closed
2025-10-05T17:18:32.458621Z [info ] pipeline_completed [__main__] pipeline_id=etl_20251005_121829 processing_time=3.106952 status=success
2025-10-05T17:18:32.473669Z [info ] metrics_saved [__main__] filepath=data\output\metrics\metrics_etl_20251005_121829.json
======================================================================
PIPELINE COMPLETED SUCCESSFULLY
======================================================================
pipeline_id: etl_20251005_121829
status: success
total_input: 10500
total_loaded: 9322
success_rate: 88.78%
duplicates_removed: 0
validation_errors: 100
processing_time: 3.11s
======================================================================